Flexible Dataset Integrator (fdi)
FDI helps data producers and processors to build connections into isolated heterogeneous datasets. to assemble, organize, and integrate data into self-describing, modular, hierarchical, persistent, referenceable Products, whose component datasets keep their own characteristics and are easily accessible.
Features
With FDI one can pack data of different format into regular and modular data Products, together with annotation (description, types, units, defaults, and validity specifications) and meta data (data about data). One can make arrays or tables of Products using basic data structures such as sequences (e.g. Python list), mappings (e.g. Python dict), or custom-made classes. FDI accomodates nested and highly complex structures.
Access APIs of the components of FDI data objects are convenient and similar to those of standad Python libraries, making it easier for scripting and data mining directly ‘on FDIs’.
All levels of FDI Products and their components (datasets or metadata) are portable (serializable) in human-friendly standard format (JSON implemented), allowing machine data processors on different platforms to parse, access internal components, or re-construct a product. Even a human with only a web browser can understand the data.
The tring() method of major containers classes outputs nicely formated (often tabulated) text description of complex data to help inspection.
Most FDI Products and components implement event sender and listener interfaces, helping scalable data-driven processing pipelines and visualizers of live data to be constructed.
FDI stoerage ‘pools’ (file, network, or memory based) are provided as references for 1) queryable data storage and, 2) for all persistent data to be referenced to with URNs (Universal Resource Names).
FDI provides Context type of product so that references of other products can become components, enabling encapsulation of rich, deep, sophisticated, and accessible contextual data, yet remain light weight.
For data processors, an HTML server with RESTful APIs is implemented (named Processing Node Server, PNS) to interface data processing modules. PNS is especially suitable for Docker containers in pipelines mixing legacy software or software of incompatible environments to form an integral data processing pipeline.
This package attempts to meet scientific observation and data processing requirements, and is inspired by data models of, and designs APIs as compatible as possible with, European Space Agency’s Interactive Analysis package of Herschel Common Science System (written in Java, and in Jython for scripting).
FDI Python packages
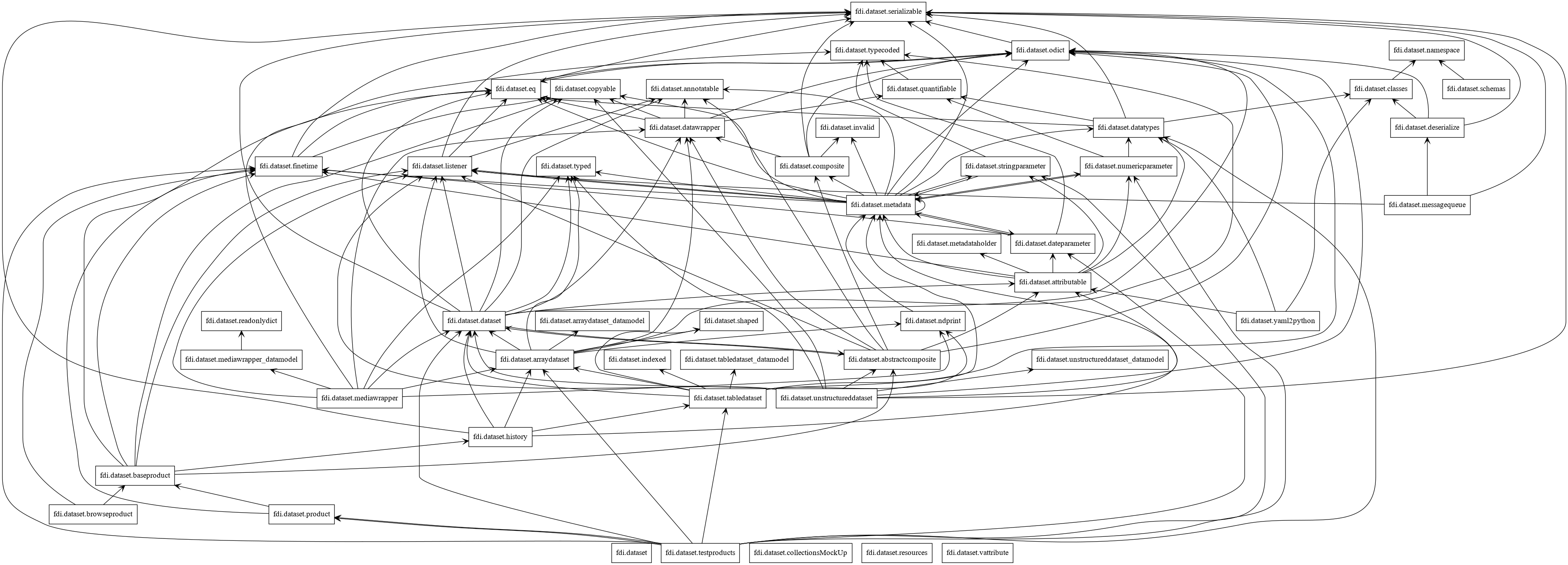
The base data model is defined in package dataset.
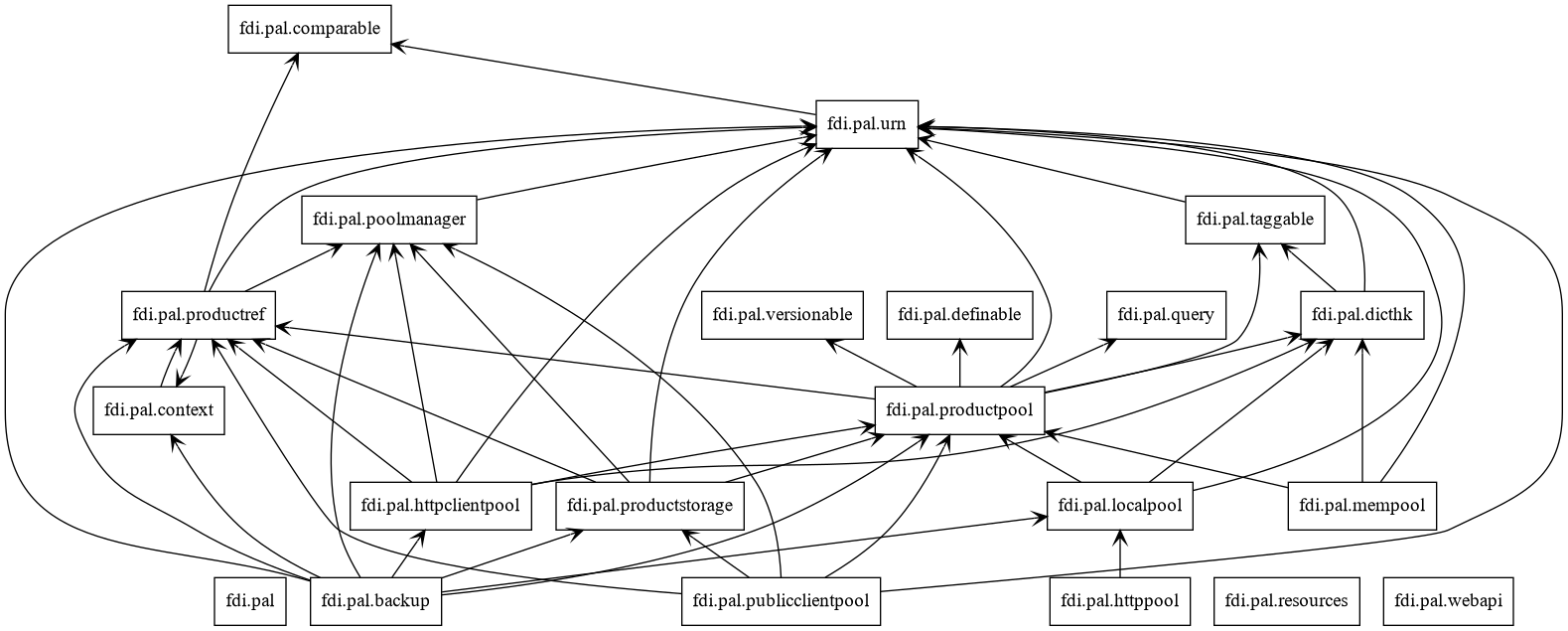
Persistent data access, referencing, querying, and Universal Resource Names are defined in package pal.
A reference REST API server designed to communicate with a data processing docker using the data model is in package pns.
A reference REST API server to provide a web interface between a pool on the server and a data user in package http pool.
API Document
API: