dataset: Model for Data Container
Rationale
A data processing task produces data products that are meant to be shared by other people. When someone receives a data ‘product’ besides datasets s/he woud expect explanation informaion associated with the product.
Many people tend to store data with no note of meaning attached to them. Without attach meaning of the collection of numbers, it is difficult for other people to fully understand or use the data. It could be difficult for even the data producer to recall the exact meaning of the numbers after a while.
This package implements a data product modeled after Herschel Common Software System (v15) products, taking other requirements of scientific observation and data processing into account. The APIs are kept as compatible with HCSS (written in Java, and in Jython for scripting) as possible.
Definitions
Product
- A product has
zero or more datasets: defining well described data entities (say images, tables, spectra etc…).
history of this product: how was this data created,
accompanying meta data – required information such as who created this product, what does the data reflect (say instrument) and so on; possible additional meta data specific to that particular product type.
Dataset
Three types of datasets are implemented to store potentially any data as a dataset. Like a product, all datasets may have meta data, with the distinction that the meta data of a dataset is related to that particular dataset only.
- array dataset
a dataset containing array data (say a data vector, array, cube etc…) and may have a unit.
- table dataset
a dataset containing a collection of columns. Each column contains array data (say a data vector, array, cube etc…) and may have a unit. All columns have the same number of rows. Together they make up the table.
- composite dataset
a dataset containing a collection of datasets. This allows arbitrary complex structures, as a child dataset within a composite dataset may be a composite dataset itself and so on…
Metadata and Parameters
- Meta data
data about data. Defined as a collection of parameters.
- Parameter
- named scalar variables.
This package provides the following parameter types:
_Parameter_: Contains value (classes whitelisted in ParameterTypes)
_NumericParameter_: Contains a number with a unit.
Apart from the value of a parameter you can ask it for its description and -if it is a numeric parameter- for its unit as well.
History
The history is a lightweight mechanism to record the origin of this product or changes made to this product. Lightweight means, that the Product data itself does not records changes, but external parties can attach additional information to the Product which reflects the changes.
The sole purpose of the history interface of a Product is to allow notably pipeline tasks (as defined by the pipeline framework) to record what they have done to generate and/or modify a Product.
Serializability
In order to transfer data across the network between heterogeneous nodes data needs to be serializable. JSON format is used considering to transfer serialized data for its wide adoption, availability of tools, ease to use with Python, and simplicity.
run tests
In the install directory:
make test
You can only test sub-package dataset, pal, pns or pns server self-test only, by changing test above to test1, test2, test3, test4, respectively. To pass command-line arguments to pytest do
make test T='-k Bas'
to test BaseProduct in sub-package dataset.
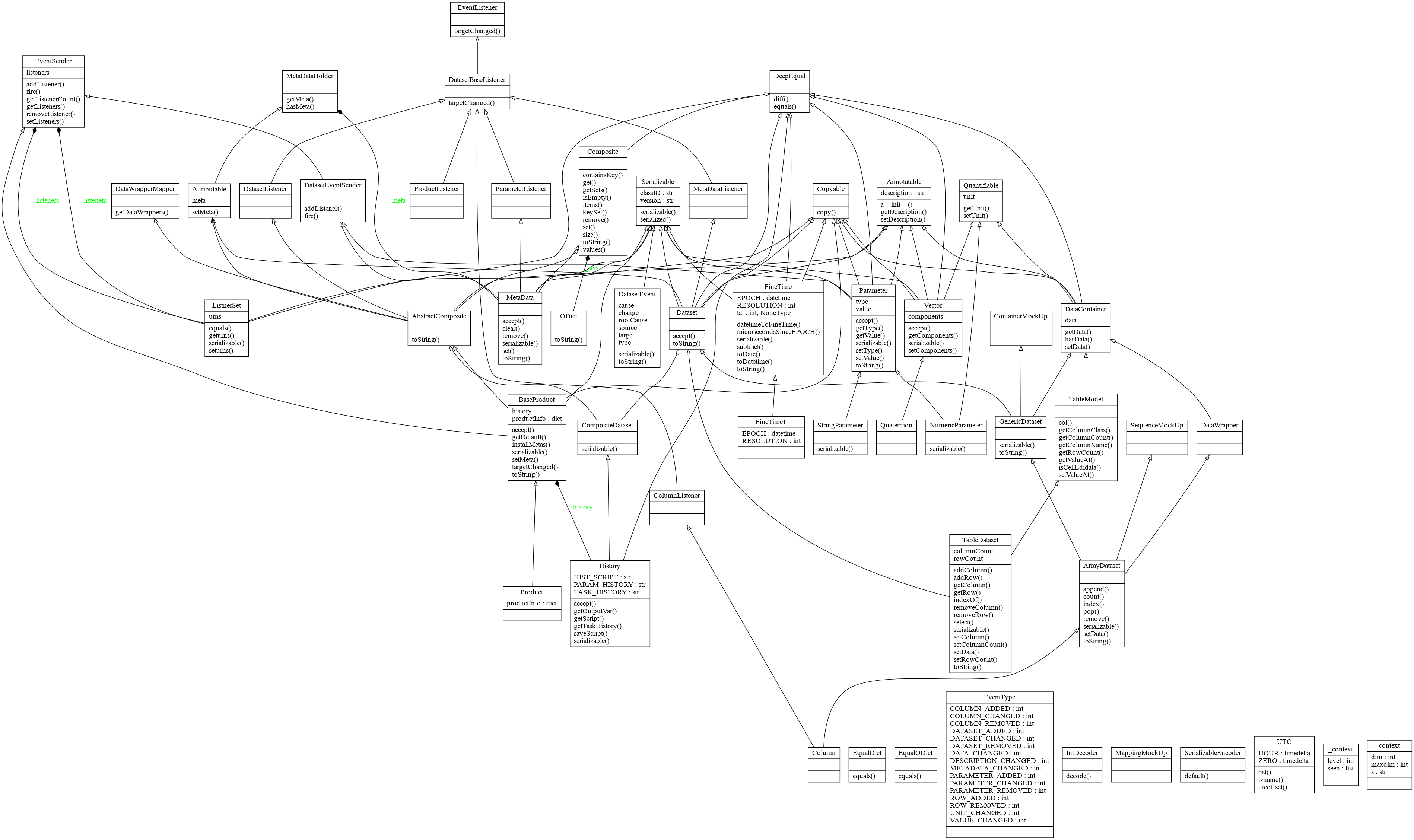
Design
Packages
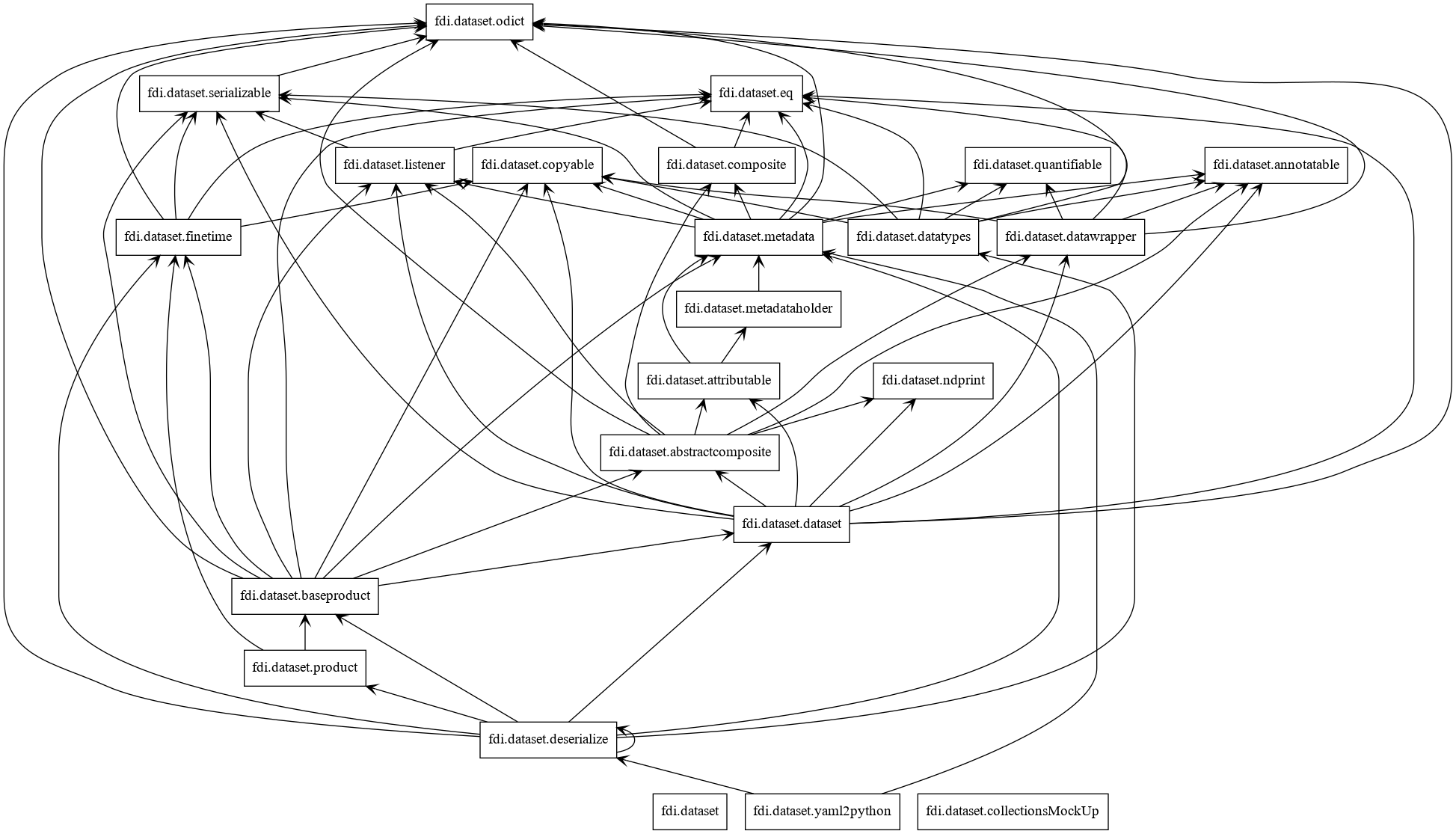
Classes